GitHub Stars and the h-index: A Journey
Starring a repo on GitHub is an easy way to tell its author that you appreciate their work. It only takes one click!

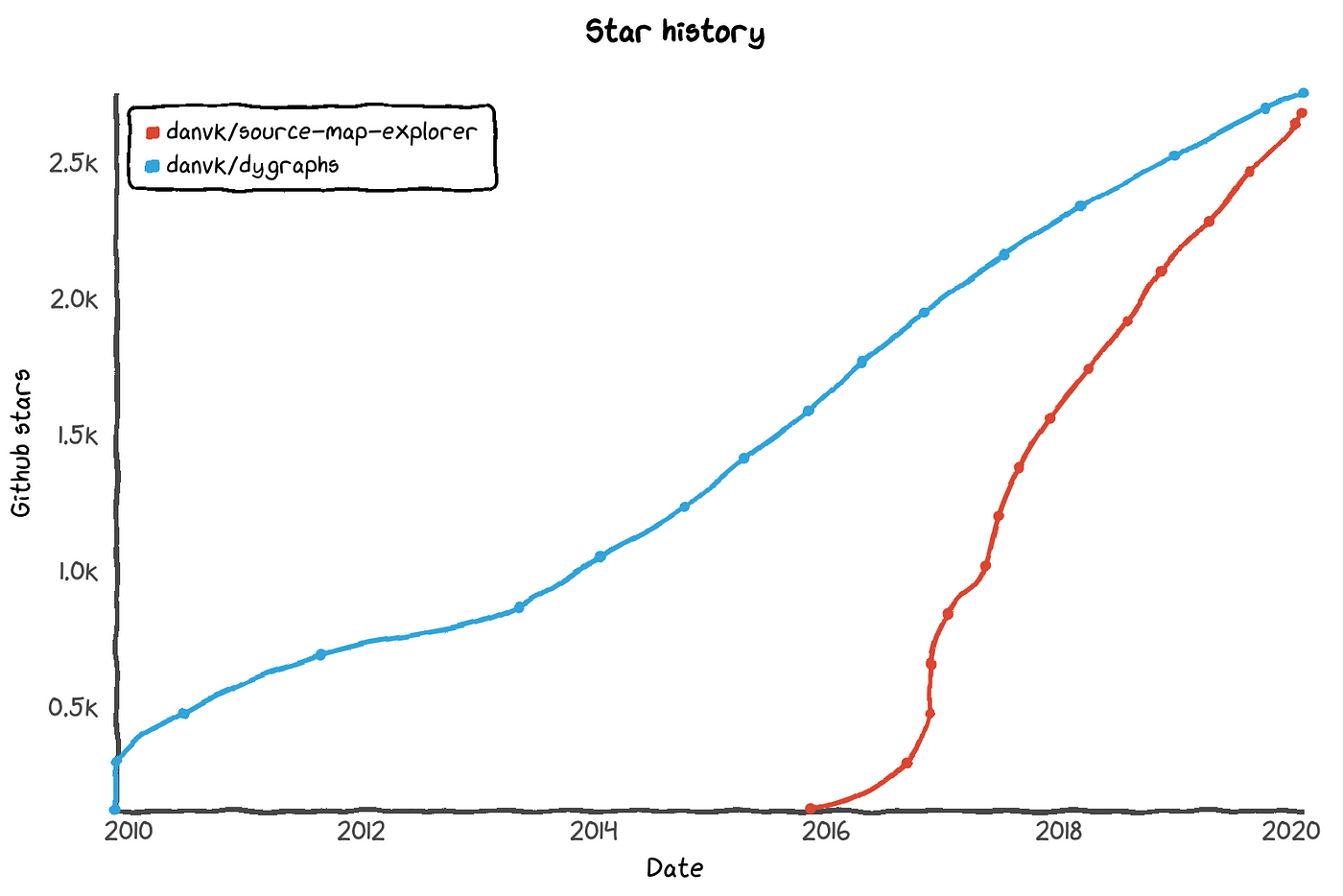
Stars are a good way to get a quick sense of a repository’s popularity. People get pretty obsessed with tracking stars. If you want to chart your stars over time, there’s star-history:
If you want to see how you stack up compared to other users, organizations and repos, there’s Gitstar Ranking:

With over a million stars across all its repos, google is #1. I have a more modest 6,678, good enough for a rank of 967.
But is the sum of stars across repos the best metric for measuring impact? Just one popular repo can push an organization to the top of this list. freeCodeCamp is at #8 with 344k stars. But 308k (nearly 90%) of those come from just one repo. What if we want to find organizations with many popular repos?
Academics face the same problem in measuring the impact of authors and journals. They’ve come up with a clever solution call the h-index. It’s best explained through an example: if you have ten published articles with more than ten citations each, then your h-index is ten. This eliminates the problem of a single popular article: if you’ve only written one article then your h-index is one, no matter how popular it is.
I thought it would be interesting to measure the h-index of GitHub users and organizations. First step: assemble a list of all the GitHub repos!
(If you want to skip ahead, here’s a page with the results)
If you have a list of all the repos with 15 or more stars, then you can find all the organizations with an h-index of 15 or higher. There are around a million of these, so this is a large but not enormous data set. I’d hoped to find a CSV file with this sort of data: just the repo name and star count would be enough.
I did some Googling and came up empty handed. There’s a GitHub integration with Google’s Bigquery, but this had more granular data than I was interested in: things like source code and commit messages. So far as I could tell, it doesn’t have a “number of stars” column anywhere.
I took a look at the list of Awesome Public Datasets and, while there are a few related to GitHub, they also didn’t have repo-level data.
GitHub has a great GraphQL API. You can use it to run searches and get back just the information you want:
When you run this, you get a result like this:
You can request up to 100 results at a time. There are 704,279 results, so we’d have to step through ~7,000 pages of results to get them all. With enough time that’s doable. But unfortunately, after 10 pages, you run up against a hard limit of 1,000 results for a single query. This makes things much more difficult!
One idea is to change the query to select a star range to get under the 1,000 result cap. Instead of “stars:>15” we could search for “stars:>15000”, “stars:9000..15000”, “stars:7000..9000”, etc. So long as each of these has fewer than 1,000 results, we can collect them all:
As you go down, the star range gets narrower and narrower for the same number of results. And by the time you get down to 123 stars (far more than 15!), there are already more than 1,000 repos with exactly that many stars. So much for this approach! We’ll have to find some other way to get under the 1,000 result cap.
At this point I asked how to do this on Stack Overflow: How can I get a list of all public GitHub repos with more than 20 stars? This is a modern form of rubber duck debugging: in forcing yourself to ask your question in a precise form, you may just realize the solution. And you can contribute that solution to the world. Or maybe someone else will have a clever solution you never thought of!
GitHub’s advanced search also lets you filter by the date that a repo was created. This lets us split the results for a range of stars into smaller chunks that can be fully scraped:
Although there are over 1,000 repos with 400–420 stars, we can get under the cap by carefully slicing the creation years. This is better than slicing the star range since, unlike star counts, creation dates can’t change while we’re querying.
Slicing by year helps but still isn’t enough to get us under the 1,000 cap for lower star counts (there are 1,099 repos with exactly 38 stars created in 2016). To get down to 15 stars, we need to slice by months and days.
The general approach is to get the number of results for a star+date range. If there are too many, we split the date range in half. If we keep repeating this, we’ll eventually be able to get the full result set.
Here’s the code:
It’s important to star from a low star range and go up. This is because repos are more likely to gain stars than lose them. If you scraped from the high star range down, you might miss a repo if it gains a star between queries. If you scrape from the low range up, you’ll only miss repos that lost a star, which is less common.
For low star counts, the date ranges have to get quite narrow:
Each of these ranges is only about a week. But with enough time, we can get all the repos! In the end, I collected all the repos using 1,102 distinct searches. Here’s a link to the full CSV file (~50MB).
So after all that, who has the highest h-index? Here’s the list:
Google is still at the top with an h-index of 347 and Microsoft keeps its number two spot. But Facebook, which is #3 by total stars, drops all the way to #12 with an h-index of 125. In other words, they have fewer repos but on average their repos are quite popular. My h-index is 16, which ranks #1,423 amongst individuals. This is lower than my ranking based on total stars, which reflects my having two repos (dygraphs and source-map-explorer) which are more popular than all the rest of mine combined.
Here’s a list of all the orgs / users with an h-index of 40+, along with the accompanying data going down to 15.
Here’s a table of the top 50 by h-index compared with their rankings on Gitstar:
There are several organizations/users that do much better on h-index than total starpower:
- fossasia (4 vs. 13, h-index of 206)
Open Technologies developed in Asia and Around the Globe - spatie (9 vs. 65, h-index of 132)
Webdesign agency based in Antwerp, Belgium; lots of PHP repos. - codrops (10 vs. 123, h-index of 132)
Web design blog with lots of examples - Azure (12 vs. 76, h-index of 124)
- awslabs (14 vs 62, h-index of 118)
- GoogleCloudPlatform (16 vs. 93, h-index of 112)
(cloud hosts) - mapbox (17 vs. 98, h-index of 108)
Mapping platform for web & mobile
